-
[MySQL] LeetCode 185. Department Top Three Salaries 문제풀이, 답학습기록 : 데이터 분석 2025. 4. 15. 09:57
문제
난이도 Hard | Topics | Companies | SQL Schema > Pandas Schema
Table: Employee
+--------------+---------+ | Column Name | Type | +--------------+---------+ | id | int | | name | varchar | | salary | int | | departmentId | int | +--------------+---------+ id is the primary key (column with unique values) for this table. departmentId is a foreign key (reference column) of the ID from theDepartmenttable. Each row of this table indicates the ID, name, and salary of an employee. It also contains the ID of their department.Table: Department
+-------------+---------+ | Column Name | Type | +-------------+---------+ | id | int | | name | varchar | +-------------+---------+ id is the primary key (column with unique values) for this table. Each row of this table indicates the ID of a department and its name.A company's executives are interested in seeing who earns the most money in each of the company's departments. A high earner in a department is an employee who has a salary in the top three unique salaries for that department.
Write a solution to find the employees who are high earners in each of the departments.
Return the result table in any order.
The result format is in the following example.
Example 1:
Input: Employee table: +----+-------+--------+--------------+ | id | name | salary | departmentId | +----+-------+--------+--------------+ | 1 | Joe | 85000 | 1 | | 2 | Henry | 80000 | 2 | | 3 | Sam | 60000 | 2 | | 4 | Max | 90000 | 1 | | 5 | Janet | 69000 | 1 | | 6 | Randy | 85000 | 1 | | 7 | Will | 70000 | 1 | +----+-------+--------+--------------+ Department table: +----+-------+ | id | name | +----+-------+ | 1 | IT | | 2 | Sales | +----+-------+ Output: +------------+----------+--------+ | Department | Employee | Salary | +------------+----------+--------+ | IT | Max | 90000 | | IT | Joe | 85000 | | IT | Randy | 85000 | | IT | Will | 70000 | | Sales | Henry | 80000 | | Sales | Sam | 60000 | +------------+----------+--------+ Explanation: In the IT department: - Max earns the highest unique salary - Both Randy and Joe earn the second-highest unique salary - Will earns the third-highest unique salary In the Sales department: - Henry earns the highest salary - Sam earns the second-highest salary - There is no third-highest salary as there are only two employeesConstraints:
- There are no employees with the exact same name, salary and department.
문제 파악하기
- 부서별 최고 연봉자 Top3의 정보를 추출하되, 유니크한 연봉금액을 기준으로 해야합니다.
- 즉 연봉 금액이 공동 순위인 경우도 모두 추출하고, 다음 순위 숫자를 건너뛰지 않아야 하므로 DENSE_RANK()를 활용하겠습니다.
문제 풀이
1) 두 테이블을 조인하고, 순위를 매겨줍니다.
- 최종적으로 추출해야할 데이터는 부서명, 직원이름, 연봉금액입니다.
- 따라서 해당 직원이 소속된 부서명을 추출하기 위해 JOIN을 해줍니다.
SELECT * , DENSE_RANK() OVER (PARTITION BY d.name ORDER BY e.salary) AS rk FROM Employee e JOIN Department d ON e.departmentId = d.id
2) 연봉순위 임시테이블(WITH문)을 활용하여 메인 쿼리문에서 연봉 Top3 추출하기
WITH Salary_rk AS ( SELECT * , DENSE_RANK() OVER (PARTITION BY d.name ORDER BY e.salary) AS rk FROM Employee e JOIN Department d ON e.departmentId = d.id ) SELECT d.name AS Department , e.name AS Employee , e.salary AS Salary FROM Salary_rk WHERE rk <= 3 ORDER BY rk DESC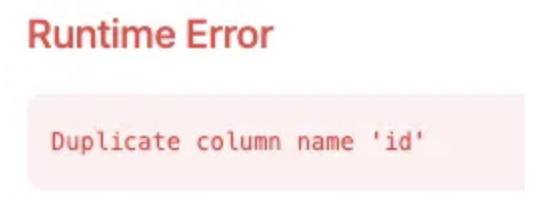
id라는 컬럼명이 중복 사용되어 발생한 에러로, 서로 다른 컬럼명으로 특정해줍니다.
WITH Salary_rk AS ( SELECT e.id , e.name AS Employee , e.salary AS Salary , e.departmentId , d.id AS Department_id , d.name AS Department , DENSE_RANK() OVER (PARTITION BY d.name ORDER BY e.salary) AS rk FROM Employee e JOIN Department d ON e.departmentId = d.id ) SELECT Department , Employee , Salary FROM Salary_rk WHERE rk <= 3 ORDER BY rk DESC
- WHERE문 조건없이 순위와 함께 다시 출력하여 확인해보기
WITH Salary_rk AS ( SELECT e.id , e.name AS Employee , e.salary AS Salary , e.departmentId , d.id AS Department_id , d.name AS Department , DENSE_RANK() OVER (PARTITION BY d.name ORDER BY e.salary) AS rk FROM Employee e JOIN Department d ON e.departmentId = d.id ) SELECT Department , Employee , Salary , rk FROM Salary_rk
→ Salary가 높은 순서로 랭킹이 매겨져야하는데 낮은 순서로 매겨져서 발생한 문제입니다.
- WITH문에서 rk를 정의할 때 정렬을 DESC로 변경해주고, 메인 쿼리문에서 다시 WHERE조건으로 1~3위를 출력해보겠습니다.
최종 쿼리문 (답)
WITH Salary_rk AS ( SELECT e.id , e.name AS Employee , e.salary AS Salary , e.departmentId , d.id AS Department_id , d.name AS Department , DENSE_RANK() OVER (PARTITION BY d.name ORDER BY e.salary DESC) AS rk FROM Employee e JOIN Department d ON e.departmentId = d.id ) SELECT Department , Employee , Salary FROM Salary_rk WHERE rk <= 3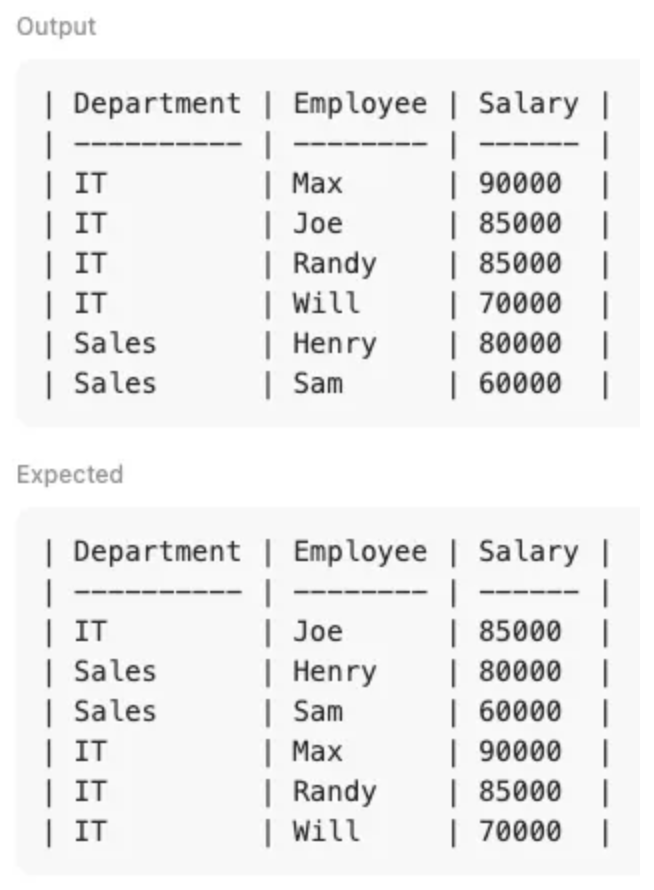
회고
KEEP
- 문제의 핵심을 정확히 이해했고, 필요한 함수를 적절히 활용했다.
- 에러가 발생하거나 문제 의도와 다른 결과가 나왔을 때 차근차근 원인을 파악하여 해결하였다.
PROBLEM
- 테이블 조인 시 컬럼명이 중복된 경우, 정렬을 반대로 한 경우로 인해 시간이 소요되었다.
TRY
- 문제의 조건을 잘 확인하면서 쿼리문을 작성하고, 꾸준히 많이 풀어보며 문제 해결 시간을 단축시켜보자!
'학습기록 : 데이터 분석' 카테고리의 다른 글
이커머스 서비스의 클래식 리텐션 구하기 (0) 2025.04.15 [MySQL] 해커랭크 : Binary Tree Nodes (0) 2025.04.14 [MySQL] 해커랭크 문제풀이 : Occupations (0) 2025.04.10 [MySQL] LeetCode 문제풀이 : 550. Game Play Analysis IV (0) 2025.04.09 [MySQL] LeetCode 문제풀이 : 1084. Sales Analysis III (1) 2025.04.08